This week, I return to my profession as a computer scientist and read the book titled “Text Data Management and Analysis – A Practical Introduction to Information Retrieval and Text mining” by ChengXiang Zhai and Sean Massung from University of Illinois at Urbana-Champaign. In Part I of the two-part blog post about this topic, I walk you through some key points of the first two sections of the book: Overview and Background, and Text Data Access. I leave the third section, Text Data Analysis, and the fourth section on a unified framework for text management and analysis to next blog post.

Overall, this book is very easy to follow. This might not be a very accurate projection from me who has worked on data-related topics in multiple areas of computer science over a decade. As far as computer science books are concerned, this statement stays true though. I would classify it as a textbook on information retrieval and text mining for 2nd or 3rd year undergraduates studying computer science, or, an entry-level book that opens the door to this field for people with a science background but specialised in other domains. If you prefer technical books of terse writing style, you may find yourself unsatisfied. It might seem to you that the authors did not make a great deal of effort to make the book concise. However, on the positive side, this means that there are very detailed explanations of concepts and how the algorithms and their associated maths formula are derived step-by-step. If you have not come across those before, you would appreciate this book’s thoroughness. There is a companion toolkit named the META toolkit available freely. It provides implementations of many techniques discussed in the book. Based on the material covered by this book, ChengXiang Zhai offers two courses on Coursera: Text Mining and Analytics and Text Retrieval and Search Engine.
Anyone who is reading this article would know that the amount of data produced per day has been increasingly dramatically over time. The characteristics of big data were summarized as 3-V: Volume (the quantity of data produced, collected, processed), Variety (incompatible data formats, non-aligned data structures, and inconsistent data semantics) and Velocity (the speed of data generation and subsequently speed requirement on analysis), by Doug Laney in his writing titled 3D Data Management. Later, the 3-V concept was expanded to 4-V (adding Veracity referring to the uncertainty of data) and 5-V (adding Value, referring to the ability to add value to business through insights derived from data analytics). Text data plays a significant role in this big data world. To process and exploit the ever-growing large amount of text data, there are two main types of services: text retrieval and text mining. The former is concerned with developing intelligent systems to help us to navigate the ocean of text data and access the most needed and relevant information efficiently and accurately. The latter focuses on discovering the purpose or intention of the text communication, deriving the semantic meaning, the underlying opinions and preferences of the users through the texts used, and by doing so assisting the users with decision making or other tasks. I am wary of using the word “knowledge” here, although it is standard practice in the writings of this field to see that extracted value from text as knowledge.
In this book, text information systems is described as offering three distinct and related functionalities: information access, text organisation and knowledge acquisition (text analysis). There are two typical ways of providing the access to relevant information to users: search engine and recommendation system. A search engine provides the users with relevant data, upon receiving certain queries from the users. Alternatively, it allows the users to browse the data through some hierarchical trees or other organisations, for example the browsing pane on Amazon site. This is typically referred to as pull model. It could be either personalised or not. A recommendation system takes a more active approach by pushing relevant information to a user as new information comes in with or without the updated user profile data. Hence it is referred to as push model. Text organisation is essential to make the information access and analytics effective. Although it is mostly hidden from a user’s perspective, it is this core part that glues the other parts of information system together. I include a drawing of a conceptual framework of text information systems from this book here for illustration purpose.
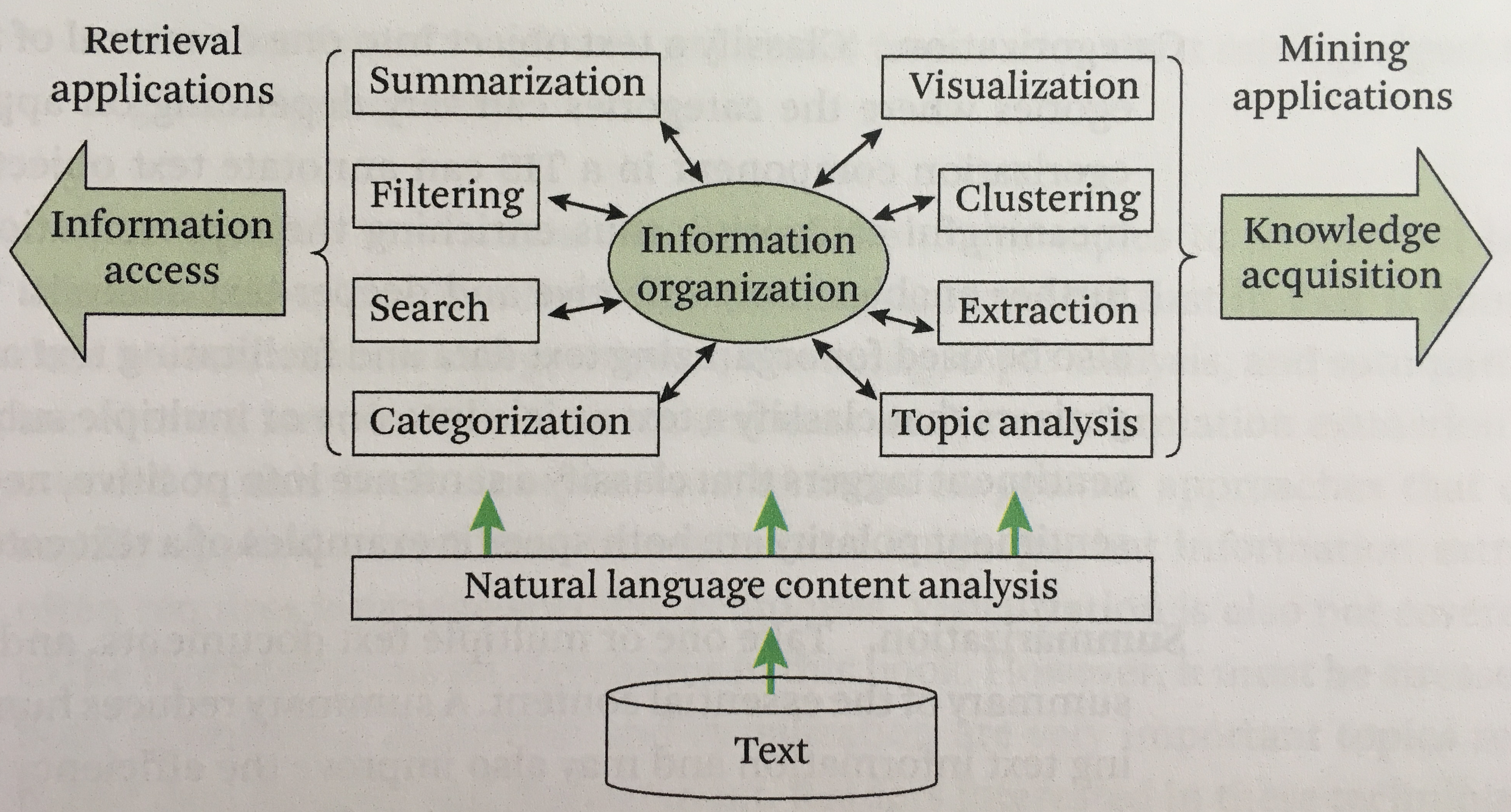
The prerequisite background knowledge for this domain include: probability and statistics, information theory and machine learning. Fear not though. Chapter 2 of the book discusses some of the basics. The appendix gives more detailed treatment on Bayesian statistics, expectation-maximisation, KL-divergence and Dirichlet prior smoothing.
The discussions on a few topics were interesting for me: statistical language models, the vector space and probabilistic retrieval models, all key components of search engine implementation (e.g., tokenizer, indexer, scorer/ranker, feedback schemes etc.), web indexing, link analysis, content-based recommendation and collaborative filtering. However, on the topics of link analysis and recommendation systems, I prefer Mining of Massive Datasets by Jure Leskovec, Anand Rajaraman and Jeff Ullman.
Happy reading!
One thought on “Text Data Management and Analysis – Information Retrieval and Text Mining – Part I”
Comments are closed.