
The third and fourth sections of this book cover text data analysis and unified text data management analysis system.
Since some topics covered in the latter half of this book are new to me, two attributes of this book were particularly helpful and eased the learning curve: the pictorial illustrations and comprehensive references accompanying the text. The drawings used to illustrate concepts played an important role for me to grasp the gist fast. Due to the very broad coverage of topics by this book, it is impossible for the authors to elaborate on all the details in depth, particularly the areas are actively being researched. The many references included in these chapters direct me to the resources to follow up on, should I wish to dive further into a specific topic. I also like the discussion of evaluations included in nearly all chapters. We cannot improve what we cannot measure. For any system being implemented, designing appropriate evaluation methods guides the development of the rest of the system.
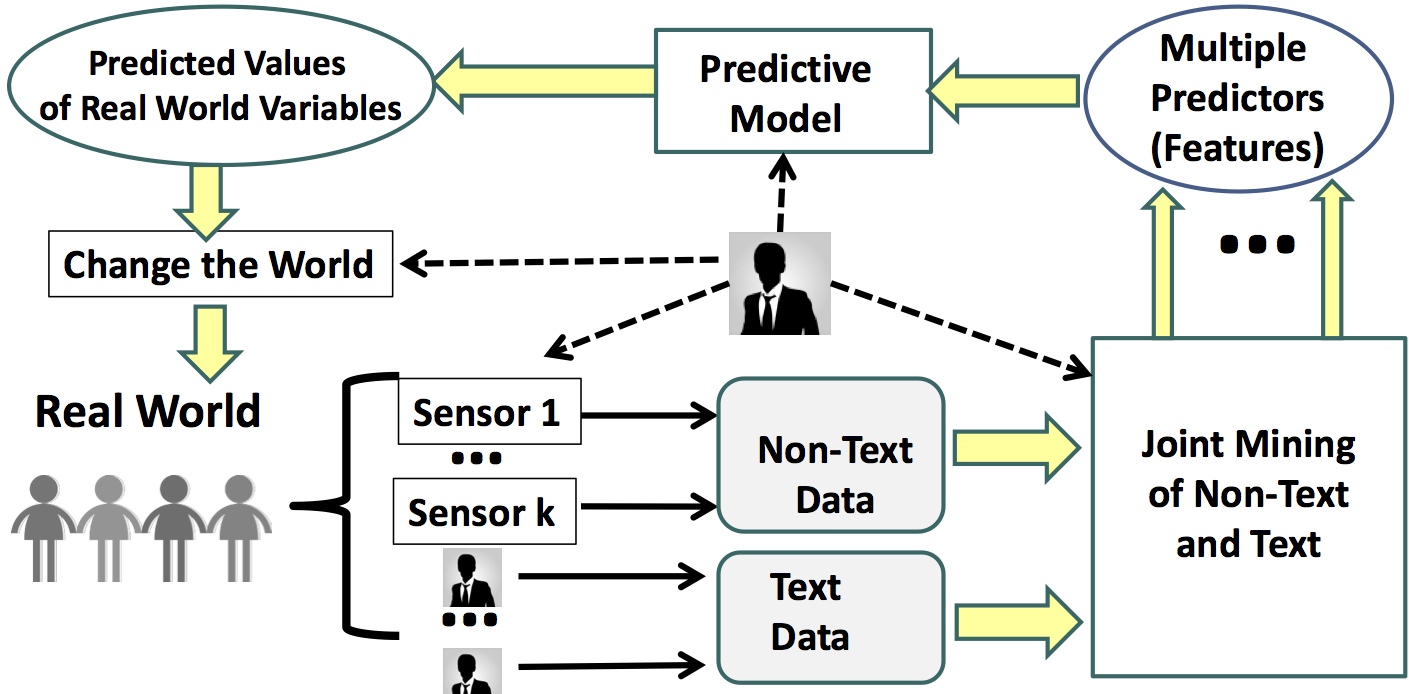
In the general framework of data mining, we humans can be viewed as subjective sensors, since the process of perceiving real-world events and describing or expressing thoughts about them in text data as a human being is very similar to how sensors like video cameras select and record some aspects of these same events. The data collected through these sensors, subjective or objective, can be in a text or non-text format. For the former, we can apply text mining; for the latter, more general data mining (e.g. image/video mining). Data mining software can be built as a combination of both or either. By applying data mining, a user hopes to derive actionable knowledge from the multi-modal and multi-source data. Through taking actions, the users in turn change the real world events and lead to newly updated data being collected. This process iterates as shown in this figure, cited from the course Text Mining and Analytics.
Section III Text data analysis starts with an entry-level introduction to text data analysis by discussing the potential applications, text vs non-text data and the landscape of text mining tasks. In the landscape of text mining tasks, the authors distinguish four types of task to infer knowledge from the data:
- mining knowledge about the natural languages used to describe our observations, opinions, and so on.
- mining the content of text data to gain knowledge about the observed world.
- mining knowledge about the observers who produced the text data.
- inferring other real-world properties and performing predictive analysis.
This section covers the following technical topics in details, and for each topic I provide a very brief description here. For further details, please refer to the book itself and the related research papers.
Word Association Mining
This entails discovering the two types of word relations: paradigmatic and syntagmatic. Words A and B have a paradigmatic relationship if we could substitute A for B or B for A without affecting the general understanding of the sentence where the word A or B occurs. This implies that A and B could be semantically or syntactically similar to each other, in other words, the two share a similar context. If words A and B have a syntagmatic relationship, they typically appear together in a context to express a coherent meaning.
The methods used for discovering these relations include examining the context of each word and compute certain similarity metrics of these contexts. To discover the correlated cooccurrences, we can use information based approaches, such as computing the conditional entropy of the occurrence of one word given the context of another word, or, computing the mutual information.
To evaluate the outcome, NDCG and average NDCG could be used to examine the ranked lists of relevance scores. Intrusion detection, using human judgement, can also check whether there is a word distinctively incoherent with the rest of the words in this word association group .
Text Clustering
Clustering allows us to discover the hidden structures in the data. The clustering techniques discussed in this chapter can be applied at both word and document level. Two categories of clustering technique are presented: similarity-based and model-based. Commonly, these clustering methods are unsupervised.
In a similarity based approach, defining one or a set of similarity metrics is a prerequisite. With a specified metric, clustering could be performed either top-down (i.e., divisive clustering) or bottom-up (i.e., agglomerative clustering). Typically in this scenario, the assignment of a word or document to a particular cluster is a hard binary one. A probabilistic model based approach typically allows soft assignment, meaning one data item could belong to multiple clusters, where each membership has a certain probability, and where all probabilities for this item sum up to one.
Text Categorization
Text Categorization goes one step further beyond clustering, as the goal here is to find the right category for text objects given a set of predefined categories. For example, we could design a program to automatically categorize each of my blog postings to the right topic category based on its content, computer science, business, history, fiction etc. What features would be useful to derive from the text for its categorisation? Recent studies show that combining the low-level lexical features with high-level syntactic features provide better performance in classification task than using either feature type alone. The book discusses three classification algorithms: k-nearest neighbors, naive Bayes, and linear classifiers.
Summarization
Text summarization builds on top of previous chapters and go one step higher up. The goal is to distill a large amount of text data into a concise summary. The key challenge here is to discover what are the important points conveyed in the full text. Two categories of methods are discussed in this chapter: extractive (selection-based) or abstractive summarization (generation-based).
The extractive approach typically splits the original document to sections, and selects relevant but not redundant sentences (or sub-sentences) from each section to form a summary without writing any new sentences. To achieve that, it applies discourse analysis and maximal marginal relevance.
The generation-based approach uses a language model to potentially write new sentences for the summary. The book gives an N-gram language model as an example, with n typically chosen to be about three to five. This approach may generate incomprehensible sentences due to its short-range nature. More advanced methods use other NLP techniques, such as named entity recognition and dependency parsers to extract the key entities and the relations among these entities from the text first. The authors refer them as actors and roles. The summary sentences are then generated by selecting from these identified entities and relationships in combination with a language model.
Topic Mining and Analysis
This chapter talks about using probabilistic topic models to discover latent topics in text data. The input to topic mining task is a set of documents and the number of topics k. The expected outputs are the k topics and, for each document, the probability that each topic is covered in the document, with the condition that the sum of the probabilities of all topic coverages for each document is one.
One approach is to use a mixture language model of two components: a background language model to account for the commonly occurring words in all documents and a topic specific model to represent the topic that we would like to discover. To discover more than one topic, this approach is generalised to a method called probabilistic latent semantic analysis (PLSA). The expectation-maximisation algorithm is used to estimate the PLSA.
Opinion Mining and Sentiment Analysis
As mentioned earlier, we human beings can be seen as subjective sensors of the real-world. The authors give the definition of “opinion” as cited from the course Text Mining and Analytics in the figure below.
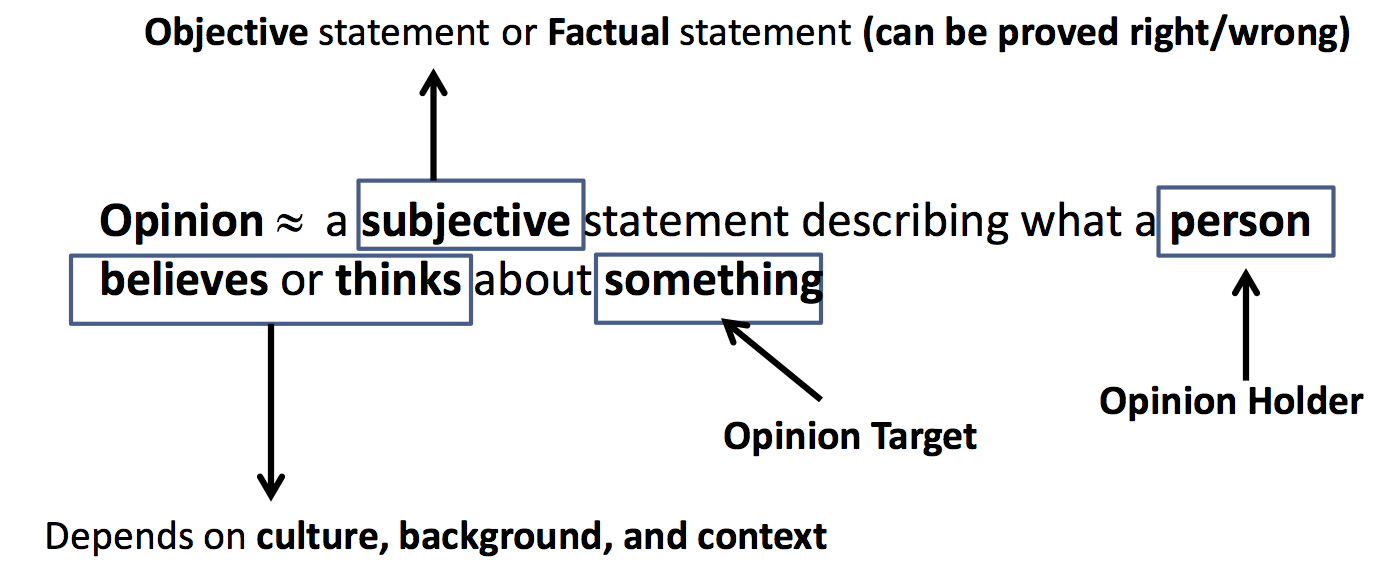
To mine the users’ opinions and discover their sentiment, the book starts with three basic opinion representations: holder, target and content of the opinion; furthermore, it covers two enriched representation: opinion context and opinion sentiment.
The sentiment classification problem can be formulated as estimating a rating in the scale of 1 to n, given a document as input. One caveat is that these ratings are not independent. On the contrary, they reflect sentiment on some scale. As a result, we cannot treat it as a categorisation task of finding the most appropriate category for the document from a set of independent categories. We can adapt the binary logistic regression to multi-level for this task. However, a better approach with fewer parameters based on a similar idea is ordinal logistic regression. Furthermore, given reviews and their overall ratings as input, the latent aspect rating analysis discussed in the chapter can generate the major aspects covered in the reviews, the ratings on each aspect, and the relative weight placed on each aspect by each reviewer.
Joint Analysis of Text and Structured Data
This chapter discusses techniques for joint analysis of unstructured text data and structured data. One example is to use the non-text data as context to facilitate topic analysis of the text data. This is more formally known as contextual text mining. Three topics covered in this chapter are of great interest: contextual probabilistic latent semantic analysis, topic analysis with social networks as context and topic analysis with time series context.
The final section of the book talks about the text analysis operators, system architecture of a unified text analysis system, and the MeTA C++ data science toolkit provided by the research group of the authors.