
Site Reliability Engineering (SRE) is a collection of articles written by dozens of Google engineers and edited by Betsy Beyer, Chris Jones, Jennifer Petoff and Niall Richard.
This book was not on my list. I had to negotiate (with myself) to remove one book and make space for this one. Why did I choose to read this book?
A week ago, together with a couple of other eBayers, I attended a two-day Service Level Objectives workshop at Google. Google has been offering this workshop to its partner companies, perhaps with some adjustment to align with the partner’s domain of interest. This was our time together.
A couple weeks ahead, one of our hosts sent us a rough plan for the workshop. I fired back, requesting more detailed schedule, breaking down to an hourly basis. My logic is simple: I can walk out (in a polite way) an unproductive meeting at my own workplace easily, but going to another company and checking in etc would be a very high overhead to pay both for me and the host, hence I need to gather enough relevant indicators to evaluate the chance of this workshop being informative and effective to justify the cost. Judging from the detailed description received, I decided this would be very useful to attend. There I went.
After a round of self-introduction, one of our hosts Jian politely asked me why I was there. I gave him the answer, in my typically brutally direct way, with full conviction: I do not let my job title define what I am interested in. I am grateful that Jian received this very well, as in some cultures and places my directness does not go well.
This workshop turned out to be very successful. My hosts were knowledge about the site reliability engineering and beyond. We had numerous discussions in an open and interactive manner. Specially, I appreciate the patience and grace of Robert van Gent, Jian Ma, Gary Luo, and Adrian Hilton in answering my many questions and discussing with me topics about service level objectives, more broadly site reliability engineering and beyond, such as software design reviews and establishing the right processes etc. I highly recommend you to participate if you are interested in this domain and offered the opportunity.
This workshop excited me enough that I decided to read Site Reliability Engineering as my book of this week. The content of the book is vast and way beyond the topic of service level objectives. It contains three main parts, each of which is detailed below.
Principles
Part I talks about the principles, underlying how SRE teams typically work—the patterns, behaviors, and areas of concern that influence the general domain of SRE operations. SRE is not only about risk assessment, management, and using the concept of error budget to quantitatively evaluate the risk tradeoffs and planning. It is also about incorporating reliability during the design phase of a project to watch out for the design flaws that could potentially lead to outage, correcting design issues or building mitigation mechanisms into the design. I love the phase “Hope is not a strategy”.
A few lessons from this part on risk management, error budget and simplicity:
Our goal is to explicitly align the risk taken by a given service with the risk the business is willing to bear. We strive to make a service reliable enough, but no more reliable than it needs to be.
Extreme reliability comes at a cost: maximizing stability limits how fast new features can be developed and how quickly products can be delivered to users, and dramatically increases their cost, which in turn reduces the numbers of features a team can afford to offer. Further, users typically don’t notice the difference between high reliability and extreme reliability in a service, because the user experience is dominated by less reliable components like the cellular network or the device they are working with.
An error budget aligns incentives and emphasizes joint ownership between SRE and product development. Error budgets make it easier to decide the rate of releases and to effectively defuse discussions about outages with stakeholders, and allows multiple teams to reach the same conclusion about production risk without rancor.
Software simplicity is a prerequisite to reliability. We are not being lazy when we consider how we might simplify each step of a given task. Instead, we are clarifying what it is we actually want to accomplish and how we might most easily do so. Every time we say “no” to a feature, we are not restricting innovation; we are keeping the environment uncluttered of distractions so that focus remains squarely on innovation, and real engineering can proceed.
Practices
Part II presents SRE practices at Google. Figures speak volumes. This service reliability hierarchy figure from the book shows the elements that go into making a service available, from the bottom up, from the most basic to the most advanced. Part II covers each level of this hierarchy: practical alerting from time-series data for monitoring; being on-call, effective troubleshooting, emergency response and managing incidents for incident response; a post-mortem culture that supports learning from failure; testing with the attempt to prevent the outage after understanding what tends to go amiss; capacity planning, load balancing to ensure the proper usage of the resource, handling the overload issue and addressing cascading failures; finally development and product launch at the top.
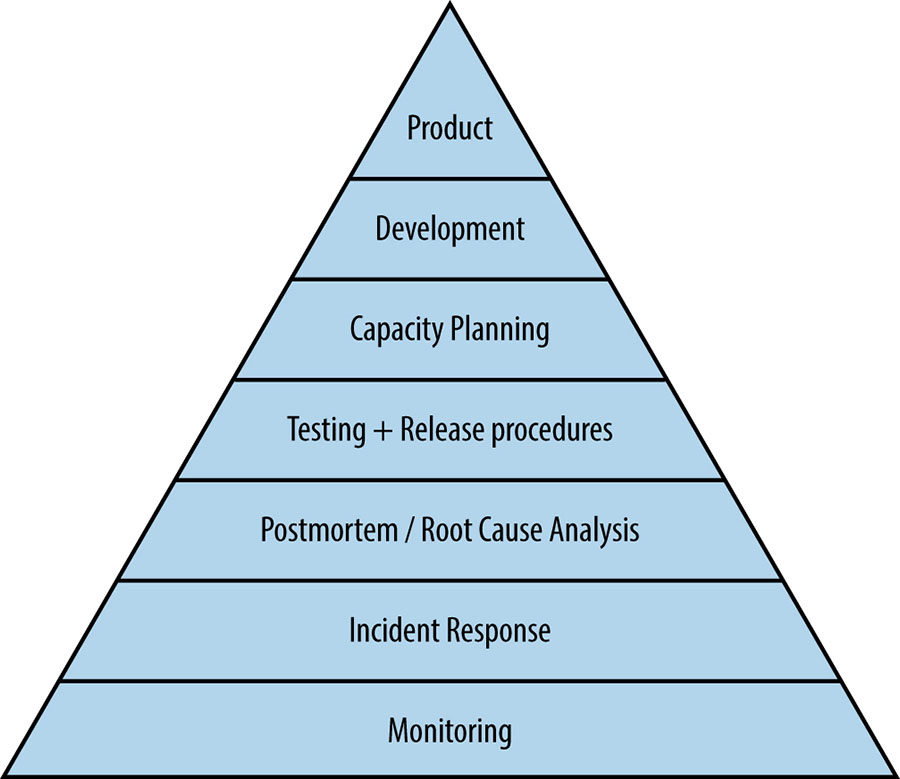
After attending the workshop at which the principles were well covered, I found Part II to be the most significant part of the book. There are vast amount of resources on these topics scattering around online, but this part of the book present them coherently with references. It would save me to search around if I wish to delve deeper into a topic.
Management
Part III covers the management topic on how SRE team works within and with other teams, some best practices for on-call and interrupts, communication and collaboration issues, and finally the evolving SRE engagement model.
For people without SRE background in companies like Google but with experience working in other domains, it is worthwhile to read the chapter comparing SRE at Google with lessons from other industries. The discussion here helps to illustrate the similarities and differences in a magnified way.
I like one unique point about this book: many chapters start with a set of key questions to ask when approaching a topic. Asking the right questions is of utmost importance. To give you an example, these are the questions for comparing SRE at Google with other high-reliability industries:
- Are the principles used in Site Reliability Engineering also important outside of Google, or do other industries tackle the requirements of high reliability in markedly different ways?
- If other industries also adhere to SRE principles, how are the principles manifested?
- What are the similarities and differences in the implementation of these principles across industries?
- What factors drive similarities and differences in implementation?
- What can Google and the tech industry learn from these comparisons?
The appendix presents tools and templates that can be used right out of box. One example is the availability table. Its calculation is straightforward. Availability is derived based on how long a service is unavailable over some period. With the assumption that there is no planned downtime, we calculate how much downtime could be forgiven to achieve a specific availability target. For example, with the availability target 99.5%, the allowed unavailability time window would be 1.83 days per year or 7.20 minutes per day or 18 seconds per hour. This is uptime and downtime-based availability. You can also calculate it as the success request rate. One common theme of this book and the workshop is to figure out what metrics to design and use. Other appendices include best practices for production services, example incident state document, example post-mortem, launch coordination checklist, and example production meeting minutes.
Last but not least, I would like to cover post-mortem analysis. It is vital to have a blameless post-mortem culture, focusing on the underlying issues and not pointing fingers at people. Services and products get so complex that it is rarely one or two persons’ fault that something is broken. In post-mortem analysis, the suggested sample covers these key areas: who are working on addressing the outage, current status of the incident, what has happened, the impact of the incident, what are the root causes, what triggered the incident, how did we detect this, what are the action items that has been taken and will be taken, is the action for prevention purpose or for mitigation, what went well in the light of handling his incident, what went wrong, what were lucky escape, and the detailed timeline from the beginning of the outage to its end. Once again, note the beauty of asking the right questions.